
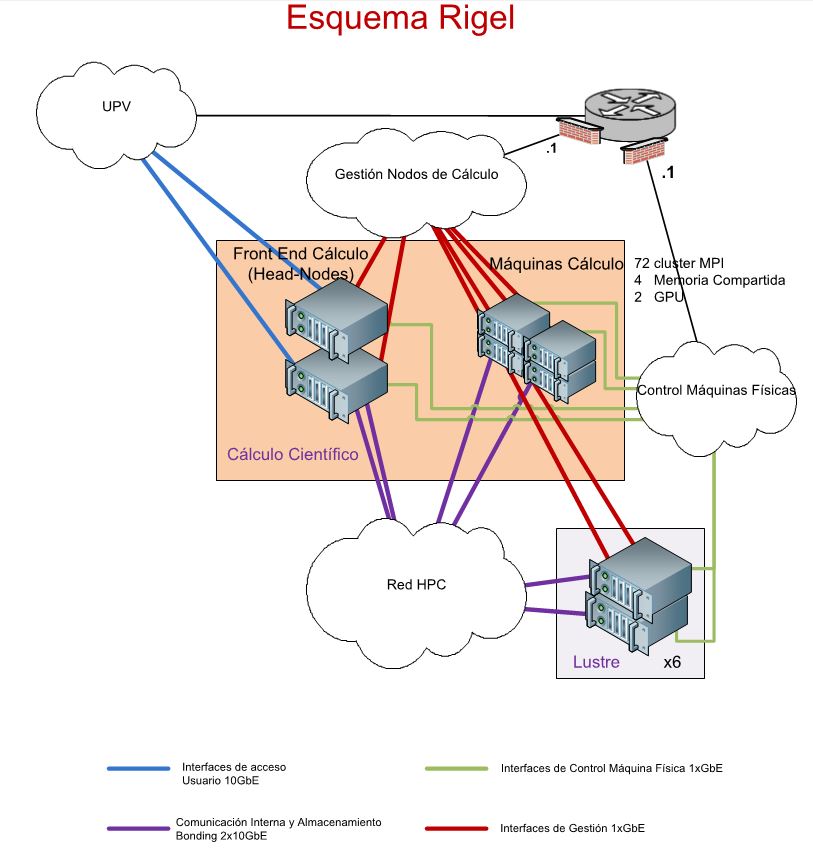
A través de financiación FEDER se ha incorporado un nuevo sistema de cálculo científico a la infraestructura ofertada por ASIC a la comunidad universitaria. El sistema se compone de:
...
El cluster para proceso paralelo masivo está original estaba compuesto por 72 nodos. Los Estos nodos del cluster son BX920S3 de Fujitsu sobre chasis blade BX900S2. Este modelo de blade incorpora 18 servidores por chasis. El cluster está formado por un total de 4 chasis. Cada nodo del chasis tiene las siguientes características:
...
El procesador E-2450 proporciona un buen compromiso entre eficiencia y consumo, el cluster alcanza una potencia de cálculo de 20,6 TeraFLOPS (en la ejecución de un test de LINPACK ).


A finales de 2015 se incorporaron 56 nuevos nodos al clúster merced a una nueva adquisición. En esta ocasión se trata de equipamiento de la marca Bull, concretamente el modelo R424E4 con las siguientes características:
- 48 unidades con:
- 2 procesadores Intel Xeon E5-2630v3 de 8 cores, 2,4 Ghz. y 20 Mb de caché L3
- 64 Gb de memoria DDR4 de 2133 Mhz
- 8 unidades con:
- 2 procesadores Intel Xeon E5-2680v3 de 12 cores, 2,5 Ghz. y 30 Mb de caché L3
- 128 gb de memoria DDR4 de 2133 Mhz
Tras esta adquisición se consiguen un total de 2176 cores y 9364 Gb de memoria, obteniéndose marcas de rendimiento de 40 TFLOPS.

Recientemente se resolvió un nuevo concurso, Acción cofinanciada por la Unión Europea a través del Programa Operativo del Fondo Europeo de Desarrollo Regional (FEDER) de la Comunitat Valenciana 2014-2020 con el Objetivo de Promover el desarrollo tecnológico, la innovación y una investigación de calidad.

Gracias a él se han incorporado al clúster 27 nuevos nodos de la marca Dell Power Edge R640.
- 2 procesadores Intel Xeon Gold 6154 de 18 cores, 3 Ghz y 25 Mb de caché
- 24 nodos con 192 Gb de memoria 2666MT/s DDR
- 5 nodos con 768 Gb de memoria 2666MT/s DDR
Con la incorporación de estos nuevos nodos la potencia de cálculo total del cluster Rigel es de 50 TFLOPS.



2) Clúster memoria compartida
...
El procesador E5-4620 proporciona buen compromiso entre eficiencia y consumo, el cluster alcanza una potencia de 2,1TeraFlops (test LINPACK).

3) Clúster GPU's
Se han incorporado dos equipos con tarjetas GPUs. Los sistemas basados en GPUs tienen cada vez más demanda, pues sus prestaciones son excelentes. Como contrapartida está su dificultad de programación pero cada vez más las aplicaciones de cálculo pueden aprovecharse de las características de las GPUs para obtener incrementos muy significativos de rendimiento.
...
El sistema está conectado a la red FibreChannel de la UPV a través de dos switches Brocade 300 de 16 bocas .

En la convocatoria de 2019 de FEDER CV PO 2014-2020 se amplía la infraestructura de almacenamiento.
Esta nueva infraestructura consiste en dos cabinas Oceanstore 5500 V5 de Huawei, una en sala principal y otra en sala de respaldo.
Conectadas en arquitectura activo–activo con las siguientes características cada cabina:
- 2 Discos flash para cache de 960GB,
- 6 discos SSD de 3,8GB y
- 75 discos rotacionales de 10TB
El sistema contempla la compresión, la deduplicación, el autotiering y la calidad de servicio.



d) Sistemas de protección de datos: backup a disco
...
Completando la instalación dos enfriadoras de agua (chiller) que refrigeran el sistema.
5) Entorno de usuario
Todos los sistemas de RIGEL (Cluster General, Cluster Memoria Compartida y Cluster GPUs) tienen instalada la misma versión de Sistema Operativo, CentOS 6, y la misma configuración, tanto del sistema operativo como librerías y utilidades.
El gestor de colas es SGE, y todo trabajo debe ser enviado a través de colas para su ejecución. Cuando un usuario se da de alta en RIGEL, se le indicará el modo de enviar sus trabajos a través de manuales y documentación en línea.
Las opciones especificadas en el envio de trabajos permiten al sistema SGE asignar a las diferentes colas los trabajos según requerimientos especificados.
El esquema de autenticación es por LDAP y la contraseña se valida con Active Directory de la UPV.
Los usuarios no pueden acceder de modo interactivo a los nodos de cálculo, sólo trabajan en los nodos de cabecera, a los que pueden acceder por ssh. El frontend de usuario es un cluster en alta disponibilidad de dos sistemas, y su dirección es rigel.cc.upv.es
El directorio home del usuario está montado en /home/grupo/usuario en todos los nodos de todos los clusters.
El sistema tiene programas de aplicación instalados que pueden ser utilizados por cualquier usuario. Se recomienda consultar la lista y el manual de uso de los mismos.
Para los usuarios que necesiten compilar sus aplicaciones, pueden hacerlo con los compiladores estándar de Linux (gcc/g77) y los compiladores Intel Fortran e Intel C/C.
6) Acceso básico
En Rigel estan instalados los compiladores de Intel y GNU.
Por defecto, el entorno de usuario está preparado para usar los compiladores GNU.
También las ordenes mpicc, mpif77 y mpif90 que se encuentran en el $PATH son versiones que usan OpenMPI y compiladores GNU.
Para usar los compiladores Intel en lugar de los GNU, basta con incluir esta linea en el fichero .bashrc del usuario:
| Bloque de código | ||
|---|---|---|
| ||
. /home/apps/envs/ompi/1.6.4/i13.1.117 |
7) Sistema de colas
Para que el uso del sistema sea lo mas efectivo posible, todos los trabajos de cálculo deben enviarse siempre por medio del gestor de colas.
En el siguiente resumen se muestran las ordenes mas importantes para enviar un trabajo al gestor de colas.
El gestor de colas le asignara recursos cuando le llegue su turno.
El gestor de colas instalado en en Rigel es SGE (SUN Grid Engine).
Ordenes del sistema de colas
Para enviar a ejecutar un script utilizar qsub script:
El sistema responderá con información sobre el trabajo enviado así como un identificador.
...
En el script se deben incluir ciertas directivas que indican al sistema de colas los recursos (memoria, procesadores, tiempo) que se requieren. Debe indicarse el entorno paralelo y numero de cpus (nodes), la cantidad de memoria por core (h_vmem), y el tiempo maximo de ejecucion (h_rt).
...
sistema
...
Si se omite el parametro -pe se asigna 1 core.
Si se omite el parametro h_vmem se establece un limite de 1 GB.
Si se omite el parametro h_rt se establece un limite de 1 hora.
Pueden verse algunos ejemplos en el directorio /ayuda/ejemplos de rigel.
Por defecto SGE deposita la salida de los trabajos en ficheros que se crean en el directorio de trabajo. El nombre de estos ficheros tiene el formato
...
.
...
donde la e significa error y la o salida. Es decir contienen los errores y el resultado de la ejecución respectivamente.
Para consultar el estado de los trabajos encolados qstat:
Sin parámetros devuelve los trabajos del propio usuario.
rigel$ qstat
job-ID prior name user state submit/start at queue slots ja-task-ID
----------------------------------------------------------------------------------------------------------------------
7284 0.00000 run.sh ico qw 07/11/2013 14:07:03 8
Donde se puede observar que el trabajo está en cola y esperando, qw.
Cuando el trabajo entra ejecución la salida nos muestra en qué cola (y nodo) se está ejecutando.
rigel$ qstat
job-ID prior name user state submit/start at queue slots ja-task-ID
-----------------------------------------------------------------------------------------------------------------
7284 0.56000 run.sh ico r 07/11/2013 14:07:12 general@hpc033.cc.upv.es 8
Con el parámetro -g t mostrará todas las tareas en paralelo para el trabajo.
Se pueden obtener los detalles de un trabajo concreto con -j identificador.
Para listar todos los trabajos de todos los usuarios es necesario usar -u '*'.
Para cancelar un trabajo:
qdel identificador
Notas
- Las colas definidas en este momento limitan el tiempo de ejecucion de un trabajo a un maximo de 144 horas y el tiempo total de cpu (numero de procesadores * tiempo de ejecucion ) a un maximo de 1000 horas. Estos parámetros se pueden ir modificando para optimizar el rendimiento del sistema.
- El cluster esta formado por 4 servidores Fujitsu RX500 de 32 cores / 265GB de RAM y 72 blades Fujitsu BX920 de 16 cores / 64GB de RAM. Todos los nodos tienen hyperthreading activado y por ello se admiten 32 tareas en los BX920 y 64 tareas en los RX500.
- Los procesadores de estos dos tipos de nodos son diferentes. En el caso del BX920 son Intel Xeon E5-2650 a 2.00GHz, y en el caso de los RX500 son Intel Xeon E7-4620 a 2.20GHz
Ejemplos de parámetros de qsub:
-pe mp 32 -l exclusive=true,h_rt=2:00:00,h_vmem=2g
(trabajo OpenMP que ocupa 1 nodo BX920 durante 2 horas)
-pe mpi 128 -l exclusive=true,h_rt=2:00:00,h_vmem=2g
(trabajo MPI que ocupa 4 nodos BX920 durante 2 horas)
-cwd
(iniciar trabajo en directorio actual en lugar de $HOME)
Mas informacion sobre el uso del sistema de colas en las paginas de manual de qsub, qstat, qdel.
SGE USer Guide
View file